

1. 初始大数据 #
1.1. 大数据的 3V 问题 #
在处理大数据时,我们必须面对所谓的3V问题:多样性(Variety)、数据量(Volume)和速度(Velocity)。
- 多样性(Variety)
- 我们需要处理结构化、半结构化、和非结构化数据:
- 结构化数据(Structured Data):采用标准化格式(如:行列表结构)
- 半结构化数据(Semi-Structured Data):Key / Value 结构(如:Json、XML)
- 非结构化数据(Un-Structured Data):文本文件、PDF、图像、视频等。
- 随着互联网、社交媒体和移动应用的发展,企业正在收集到更多的半结构化和非结构化的数据。
- 我们需要处理结构化、半结构化、和非结构化数据:
- 数据量(Volume)
- 我们需要处理巨大体量的数据(TB、PB级别)。
- 处理和存储海量级别的数据是一个巨大的挑战。
- 速度(Velocity)
- 如今数据的产生和收集的速度很快,我们对数据处理的速度要求也很高。
- 数据里需要实时或接近实时地进行处理和分析,以便快速做出决策。例如,在线交易系统和实时监控系统都需要高效的数据处理能力。
1.2. 大数据解决方案 #
单体架构(Monolithic Approach)
- 单体架构是指将所有数据存储在一个单一的系统中。
- 这种架构设计相对简单,但需要在前期仔细规划容量和性能,因为后期的扩展性较差。这意味着你需要在一开始就投入大量成本来满足未来的需求,可能会导致资源浪费。
- 此外,当系统出现故障时,整个系统将无法使用。
分布式架构(Distributed Approach)
- 高扩展性:
- 通过增加节点来处理更大规模的数据,当用户增多时,可以轻松扩展系统的处理能力。
- 前期按需配置数据节点,避免资源浪费。
- 分布式处理:
- 数据和计算任务分布在多个节点上并行处理,提高处理效率。
- 容错性与高可用性:
- 即使某个节点出现故障,整个分布式系统依然可用,不会导致系统崩溃。
2. 初始 Hadoop #
Hadoop是一个开源的分布式计算框架,旨在解决处理大规模数据的问题。它提供了一种可靠、高效的方式来存储和处理大数据集,通过将数据分布在多台机器上,使我们在处理数据时就像在使用单台机器一样。 在Hadoop核心平台上开发了许多其他工具,如Hive、HBase、Pig、Sqoop和Oozie等。 Hadoop生态系统包括了多个组件,其中最核心的包括HDFS、YARN和MapReduce。
2.1. HDFS #
- HDFS(Hadoop Distributed File System)是Hadoop中用于存储大规模数据的文件系统。它设计用于运行在廉价的硬件上,并通过数据的冗余备份来提高可靠性。
- HDFS将大文件切分成小的数据块,并将这些数据块分布式存储在集群中的多个节点上,实现了高容错性和高吞吐量的数据存储。
- HDFS 的组件:
- NN:Name Node(名称节点)
- DN:Data Node(数据节点)
- 将文件拆分为小块,并存入其中的一些节点中(DN),每一块称之为block。典型的block大小为128MB。
- NN可以跟踪所有文件的元数据(例如:文件名、目录地址、文件大小、如何切的块、有多少块、block id、块的顺序、块的位置等)
2.2. YARN #
- YARN(Yet Another Resource Negotiator)是Hadoop的资源管理器,负责集群资源的管理和作业调度。
- YARN将集群的计算资源划分为若干个容器,用于运行应用程序的任务。
- 通过YARN,Hadoop集群可以同时运行多个不同类型的应用程序,提高了集群资源的利用率。
- YARN 的三个主要组件:
- RM:Resource Manager (资源管理器)
- NM:Node Manage (节点管理器)
- AM:Application Master(应用程序控制)
- 主从架构(Master-Slave Architecture)
- 其中一个机器成为主节点,其余的机器充当工作节点
- 在主节点上会安装RM,在工作节点上会安装NM
- NM会定期向RM发送节点状态报告
2.3. MapReduce #
- 是Hadoop中用于分布式计算的编程模型和处理引擎。
- 它将计算任务分解成独立的Map和Reduce阶段,并通过将数据分布式处理在集群中的多个节点上来实现并行计算。
- MapReduce模型简化了大规模数据的处理过程,使得用户可以轻松编写并行计算任务,适用于数据处理、分析和转换等场景。
- Map:做并行计算或处理
- Reduce:对Map的输出做聚合、汇总和合并
- 一般可以用 Hive SQL、Spark SQL、Spark Scripting 作为MapReduce 的高级API进行操作
3. 初始 Spark #
Apache Spark 是一个开源的分布式计算系统,专为大数据处理和分析设计。 它提供了一个统一的引擎,支持广泛的数据处理任务,包括批处理、实时处理、机器学习和图计算。Spark 以其速度、易用性和通用性而著称。
- 存储: 它可以读取和处理存储在 HDFS、HBase、Cassandra、Amazon S3 等多种存储系统中的数据。
- 计算引擎: Spark 提供了比 MapReduce 快 100 倍的内存处理和 10 倍的磁盘处理速度,适用于批处理和实时处理。
- 资源管理: 可以运行在多种集群管理器上,包括 Hadoop YARN、Apache Mesos 和 Kubernetes,也可以在独立模式下运行。
- 数据处理模型: Spark 提供 RDD(弹性分布式数据集)、DataFrame 和 Dataset 等,支持更复杂的数据处理任务,并且编程模型更为简洁和灵活。
- 生态系统: Spark 虽然是一个独立的项目,但与 Hadoop 生态系统兼容,可以与 Hadoop 工具和数据源无缝集成,同时也有自己的扩展组件,如 Spark SQL、Spark Streaming、MLlib 和 GraphX。
- 支持语言: Java、Scala、Python、R
3.1. Spark 的两种设置 #
- With Hadoop (Data Lake)
Spark 可与 Hadoop 生态系统集成。这意味着 Spark 在 Hadoop 分布式文件系统(HDFS)上运行,利用 Hadoop 的资源管理器(如 YARN)来管理集群资源。 这种设置通常被称为 Data Lake,因为数据通常存储在 Hadoop 的分布式文件系统中,同时利用 Spark 进行数据处理和分析。
- Without Hadoop (Lake House)
Spark 也可独立于 Hadoop。这意味着 Spark 在云环境(如 AWS、Azure、Google Cloud)或者私有数据中心中独立运行,而不依赖于 Hadoop 分布式文件系统或资源管理器。 这种设置通常被称为 Lake House,因为数据存储在云存储系统(如 Amazon S3、Azure Data Lake Storage)或其他存储系统中,同时利用 Spark 进行数据处理和分析。 Cloud Lake House背后的驱动是Databricks Spark平台。
3.2. Spark 架构 #
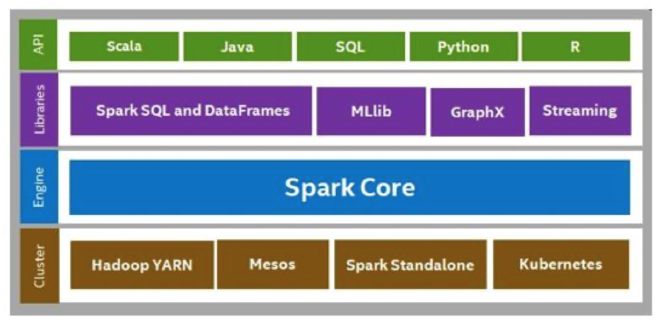
- Cluster: Spark本身不管理集群,它只给你一个数据处理框架。需要借助其它工具,如:YARN、Kubernetes、Mesos等
- Engine:
- Spark 引擎负责将数据处理任务分解为更小的任务,并在集群上调度这些任务以实现并行执行。
- 它提供了数据管理和监视功能,使得用户可以有效地管理和监控任务的执行情况。
- 此外,Spark 引擎还具有容错能力,能够在任务失败时进行恢复,确保数据处理的连续性。
- 它还负责与集群资源管理器和数据存储管理器进行交互,以确保任务能够在集群上顺利运行,并能够有效地访问和管理数据。
- Spark SQL: 使用户能够使用 SQL 来查询数据。
- DataFrames:可以使用函数式编程风格来处理和分析数据,例如:Python、Scala、Java。
- MLlib:提供了一个机器学习库,用于在大规模数据上进行机器学习和数据挖掘任务。
- GraphX:提供了一个图计算库,用于在大规模图数据上进行图计算任务。
- Spark Streaming:提了一个用于实时数据处理的模块。它使得用户能够通过在小批量数据上执行 Spark 任务来处理实时数据流。