

1. 定义 DataFrame 转换 #
Spark DataFrame 是一种不可变的数据结构,允许通过数据转换(Transformation)将一个 DataFrame 转换为另一个 DataFrame,而不会修改原始的 DataFrame。
-
DataFrame 转换类型包括:
- 组合多个 DataFrames:如 Join 和 Union 操作。
- 聚合和汇总:包括 grouping、windowing 和 rollups 操作。
- 应用函数和内置转换:包括 filtering、sorting、splitting、sampling 和 finding unique。
- 使用和实现内置函数、列级函数和用户自定义函数。
-
具体的常用转换操作:
- 过滤:使用 where() 方法根据条件筛选数据。
- 选择:使用 select() 方法选择要保留的列。
- 排序:使用 orderBy() 方法对数据进行排序。
- 分组:使用 groupBy() 方法对数据进行分组。
- 聚合:使用聚合函数(例如 count()、sum()、avg())对分组后的数据进行聚合。
-
例子:
filtered_df = df.where("Age < 40") \ .select("Age", "Gender", "Country", "state") grouped_df = filtered_df.groupBy("Country") count_df = grouped_df.count() count_df.show()- 每一次转换都会生成一个DataFrame。
2. 窄依赖转换 #
- 窄依赖转换(Narrow Dependency Transformations)是指每个分区的数据只需要其本身就可以完成操作,不需要和其他分区的数据进行交互。
- Spark 执行器上可以在它们的分区上执行,不依赖于其他的执行器和分区,最终组合这些执行器的结果得到总体的结果。
- 窄依赖转换的执行效率高,因为不需要额外的 shuffle 操作。
- 比如
where,select是窄依赖转换。
3. 宽依赖转换 #
- 宽依赖转换(Wide Dependency Transformations)是指每个分区的数据需要和其他分区的数据进行交互才能完成操作。
- 需要其它分区的数据才能产生正确的结果,通过简单的组合不能得到总体的结果。
- 比如
groupBy是一个宽依赖转换(orderBy、join、distinct等都是宽依赖转换)。 - 解决方法:
- Shuffle & Sort Operation: 合并所有的分区,然后创建一些新的分区确保同一组的数据在同一个分区内。
- 再使用聚合函数就可以合并多个分区的结果了(窄依赖)。
- 我们不需要做任何事,Spark 在内部会帮我们处理好。
- 宽依赖转换的执行效率通常低于窄依赖转换,因为需要额外的 shuffle 操作。
4. 惰性求值 #
- 惰性求值(Lazy Evaluations)是一种函数式编程技术。
- Spark 采用惰性求值策略,这意味着只有在 行动操作(Action Operation)执行时,Spark 才会真正对数据进行计算。行动操作包括:
read、write、collect、show等。collect操作将DataFrame 作为 Python 列表返回。
- 在执行行动操作之前,Spark 不会对数据进行任何计算,而只是将要执行的操作记录在 执行计划(Execution Plan)中。这样可以提高 Spark 的性能,因为只有在需要的时候才会对数据进行计算。
- 在需要立即得到结果的情况下,可以使用
collect()方法将 DataFrame 的内容收集到本地。 - 为了提高性能,可以尽量将多个窄依赖转换组合在一起,减少 shuffle 操作的次数。
- 可以使用 Spark UI 来查看执行计划,了解 Spark 如何执行查询。
5. 窥视 Spark 如何转换 Jobs、Stages 和 Tasks #
-
首先我们需要简单了解一下如何对数据分区:
- 通过
partitioned_df = df.repartition(2)对 DataFrame 强制性划分2个分区。 - 有些分区不是我们主动操作的,例如 DataFrame 经过宽依赖转换后会进行 shuffle/sort,这种情况下我们并不能确定 Spark 会把 DataFrame 划分了多少个分区。
- 可以在
spark.conf里进行设置,添加下面的语句:spark.sql.shuffle.partitions = 2 spark.conf文件的详细设置可以参考上一篇文章。
- 可以在
- 通过
-
Spark UI 只能在程序运行时查看
- 可以在代码末尾加上
input("Press Enter to continue...")防止程序结束。 - 运行后可以用浏览器打开
localhost:4040查看。
- 可以在代码末尾加上
-
关于 jobs、stages 和 tasks 的一些特性:
- 工作流程:Spark 程序 -> jobs -> stages -> tasks
- 每一个 Action 都会转化为一个 job
- 每一个 job 至少含有一个 stage 和一个 task
- 每个 stage 至少有一个 task
- 每个 task 是分配给 executors 的一个工作单元
-
以下面代码为例,Spark 会把这部分转换成1个 job,然后再把这个 job 划分成3个 stages
- 注意这部分代码中的
repartition和groupBy会引起 shufflepartitioned_df = df.repartition(2) count_df = partitioned_df.where("Age < 40") \ .select("Age", "Gender", "Country", "state") \ .groupBy("Country") \ .count() logger.info(count_df.collect())- stage1:
repartition-> 1 task- 这个 stage 里有一个任务,就是将 DataFrame 划分了两个区
- stage2:
where、select、groupBy-> 2 tasks- 由于上一步有两个分区,所以这个 stage 有两个 tasks ,每个 task 都需要做
where、select和groupBy
- 由于上一步有两个分区,所以这个 stage 有两个 tasks ,每个 task 都需要做
- stage3:
count、collect-> 2 tasks- 由于上一步的
groupBy会进行 shuffle 操作,设置的 shuffle 分区数量为2,所以这个 stage 依旧会使用两个分区,因此是2个tasks
- 由于上一步的
- stage1:
- 注意这部分代码中的
6. Spark API 介绍 #
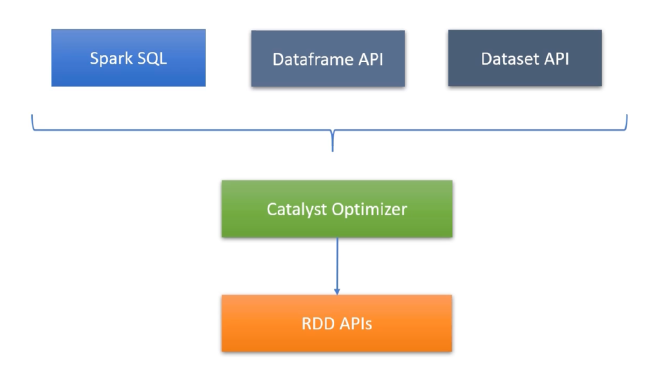
- RDD (Resilient Distributed Dataset): 弹性分布式数据集,是 Spark 最基本的数据抽象,提供了对大数据集的容错、高效处理。
- Catalyst Optimizer: 在 RDD 和高级别 API 之间存在一个 Catalyst 优化器。它负责查询优化和生成高效的执行计划。
- 高级别 API: 在 RDD 之上,Spark 引入了更高级别的 API,主要包括 Spark SQL、DataFrame API 和 Dataset API。这些 API 提供了更简洁、更高效的数据操作方式。
- Spark SQL: 允许通过 SQL 查询操作结构化数据,并集成了 SQL 语法与 Spark 的计算引擎。
- DataFrame API: 提供了类似于关系型数据库表的数据结构,使数据操作更加直观、简便。 (前面已经介绍过很多例子)
- Dataset API: 提供了强类型的 API,与 RDD 类似,但具有更高的优化和更好的编译时类型安全性。要使用 Dataset API,必须使用基于 JVM 的语言,例如 Scala 或 Java。
6.1. RDD 介绍 #
-
RDD API 是 Spark 中最基础的 API,尽管大部分情况下不常用,但它提供了极大的灵活性。
-
数据结构: RDD 是原生的数据集,不具备行列结构和 schema,而是被分解为多个分区,形成一个分布式的集合。
-
容错性: RDD 具有高度的容错性。每个 RDD 分区都包含如何创建和处理该分区的信息。如果某个执行器 (executor) 出现故障,相关的 RDD 分区将被重新分配到其他执行器上。
-
示例代码: 以下示例代码展示了如何创建和处理 RDD。
- 创建 RDD:
from pyspark import SparkConf, SparkContext from pyspark.sql import SparkSession conf = SparkConf() \ .setMaster("local[3]") \ .setAppName("HelloRDD") spark = SparkSession \ .builder \ .config(conf=conf) \ .getOrCreate() sc = spark.sparkContext linesRDD = sc.textFile("./data/sample.csv") # 假设这个文件不包含标题行- 处理 RDD:
- RDD 只提供了基本的转换,如
map(),reduce(),filter(),foreach()等。 - 但是 RDD 接受
lambda函数,可以应用自定义代码。
- RDD 只提供了基本的转换,如
from collections import namedtuple partitionedRDD = linesRDD.repartition(2) closRDD = partitionedRDD.map(lambda line: line.replace('"', '').split(",")) SurveyRecord = namedtuple("SurveyRecord", ["Age", "Gender", "Country", "State"]) selectRDD = colsRDD.map(lambda cols: SurveyRecord(int(cols[1]), cols[2], cols[3], cols[4])) filteredRDD = selectRDD.filter(lambda r: r.Age < 40) kvRDD = filteredRDD.map(lambda r: (r.Country, 1)) countRDD = kvRDD.reduceByKey(lambda v1, v2: v1 + v2) colsList = countRDD.collect() for x in colsList: logger.info(x) -
虽然 RDD API 提供了很好的灵活性和容错性,但在实际开发中,使用 Spark 的高级别 API 更为常见,因为它们提供了更高的抽象级别和更简洁的代码。
6.2 Spark SQL #
Spark SQL 提供了一种将 DataFrame 转换为临时视图,并使用 SQL 查询数据的强大功能。通过这种方式,开发人员可以利用 SQL 的简洁和高效来进行复杂的数据操作和分析。以下是一个示例,展示如何使用 Spark SQL 查询 DataFrame 数据。
# 将 DataFrame 创建为临时视图
df.createOrReplaceTempView("survey_tbl")
# 使用 SQL 查询临时视图中的数据
countDF = spark.sql("""
SELECT Country, COUNT(1) AS count
FROM survey_tbl
WHERE Age < 40
GROUP BY Country
""")
# 显示查询结果
countDF.show()
通过 Spark SQL,用户可以轻松地将 DataFrame 与 SQL 查询结合使用,这不仅简化了代码编写过程,还利用了 SQL 优化器(Catalyst)的优势,提升查询性能。 同时,这种方法也使得熟悉 SQL 的用户可以无缝地使用 Spark 进行大数据处理。